
Our goal is to study the complexity of convergence schemes and their limits. Sequences (viewed as evolutions) with the absorption property lead to so-called generic objects. One of our objectives is to extend this study in several directions. We are also going to analyze convergence schemes in which there are no evolutions with the absorption property, where the set-theoretic forcing plays a pivotal role.
Introduction
Let us imagine that a certain evolution system is given, starting from some initial state
and having the property that
for every two transitions ,
from the same state
it is possible to make
two further transitions ,
so that the
compositions
and are the
same, in particular, leading to the same state. It is then natural to expect that there exists a special infinite process
accumulating all possible states and in some sense absorbing all possible transitions. Specifically, denoting a fixed
transition
from to
by
, an
infinite process (evolution) can be represented as an infinite diagram of the form
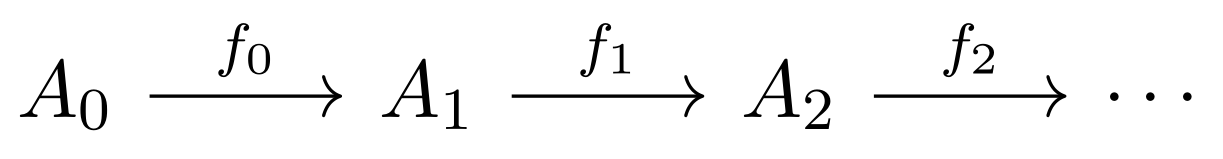
where .
Saying that such a process
second one infinitely many times.
It is rather evident that the proper framework for describing and studying such evolution systems comes from category theory. Namely, the objects are the system states while the arrows are transitions. Category theory offers here elegant and quite strong, yet at the same time manageable, tools to be utilized. Perhaps one of the basics is the concept of a functor. In order to describe an infinite transition process (evolution), it suffices to use functors from the set of non-negative integers (more traditionally denoted by ) viewed as a category in which the objects are natural numbers and arrows are pairs of the form with .
Actually, a significant power of category theory lies within the notion of
While it is possible to investigate evolution processes in their “pure” form, it is usually more convenient and more natural to look at their colimits, identifying them with the isomorphism classes of certain objects of a bigger category.
In this way we arrive at the basic concept of this project: abstract convergence scheme, namely a category
embedded into a
category consisting of
limits of sequences from .
Here, the “limit” may be either as “colimit” in the category-theoretic sense or some more general operator
acting on
Abstract convergence schemes
By an
is a category of finite (or finitely generated) models of a fixed first-order language with embeddings as arrows, while is the category of all models isomorphic to unions of countable chains in
, again with embeddings as arrows.Now is isomorphic to the union (formally: colimit) of the chain , as embeddings can always be replaced by inclusions).
Given a concrete convergence scheme, one has to first consider whether any interesting
-object
occurs as the “limit”. If so, then there is a chance that, up to isomorphism, a “special’ object occurs “most
frequently”. Of course, this needs to be made precise, either by finding a reasonable topology on the objects
of ,
where “occurring frequently” means forming a non-meager or even a co-meager
set. Another option is to find a reasonable probability measure on the objects of
, where
“occurring frequently” would mean “with positive probability” or even “with probability one”. A more
abstract approach would require considering some ideal of “small” sets whose complements are therefore
called “large”. Actually, a quite common word for “occurring most frequently” or “typically” is “being
generic”. This name has been used in the theory of set-theoretic forcing (generic filters) and
from time to time is used in descriptive set theory, when considering a complete topological
space whose elements could have various properties. Thanks to the Baire category theorem, we
can say that a fixed property is